

МЕТОДИКА ОБРАБОТКИ РЕЧЕВОГО МАТЕРИАЛА
В ходе выполнения проекта использовалась принятая при разработке корпуса ОРД методика форматирования файлов звукозаписи, отработана методика редактирования транскриптов и разработана методика подготовки речевого материала к автоматической обработке.
Этап I. Форматирование файлов звукозаписи включает следующие шаги: конвертация звукозаписей в формат PCM / 22050 Гц / 16 бит / моно, удаление пауз (фрагментов речи, не содержащих полезный речевой сигнал) длиной более 2-5 мин., членение исходных файлов звукозаписи на коммуникативные макроэпизоды, их стандартизованное описание (аннотирование) по типу, условиям и месту коммуникации, а также социальной роли говорящих.
Аннотирование коммуникативных эпизодов подразумевает указание следующих параметров:
1) тип коммуникации (например, «бытовой разговор», «профессиональная беседа», «публичная речь», «клиент-сервис»-общение, «обучение/инструктаж»),
2) условия коммуникации (в частности, «кухонные» разговоры, застолья, телефонные разговоры и т. п.),
3) социальная роль говорящих (родственники: «мать», «отец», «сын», «дочь» и др., коллеги: «начальник», «подчиненный», «коллега»; друзья; клиенты; знакомые; посторонние и др. категории),
4) место коммуникации (дом, офис, учебное заведение, магазин, кафе и др.) и выполняется согласно правилам, разработанным научным коллективом при исследовании коммуникативных сценариев (правила аннотирования макроэпизодов были разработаны в 2012-2014 при поддержке гранта РГНФ № 12-04-12017 - подробнее см. Шерстинова Т. Ю. Коммуникативные макроэпизоды в корпусе повседневной русской речи «ОДИН РЕЧЕВОЙ ДЕНЬ»: принципы аннотирования и результаты статистической обработки // Труды Международной конференции «КОРПУСНАЯ ЛИНГВИСТИКА-2013». СПб, 2013. Pp. 449–456.  ).
).
Этап II. Выборочная расшифровка звукозаписей (первичное аннотирование) выполняется в среде мультимедийного аннотатора ELAN по принципам, принятым для расшифровок корпуса ОРД. Текст каждой реплики сопровождается ее привязкой к временным отчетам на звуковой волне. Осуществлено аннотирование звукового материала по 7 стандартным уровням, принятым в корпусе ОРД (реплика с указанием синтагматического членения, код говорящего, коммуникативный микроэпизод — обязательные уровни; невербальные аудиособытия, качество голоса, фонетический комментарий, общий комментарий — факультативные параметры).
Принципы аннотирования корпуса ОРД описаны в статье:
Шерстинова Т. Ю., Степанова С. Б., Рыко А. И. Система аннотирования в звуковом корпусе русского языка «Один речевой день» // Мат-лы XXXVIII международной филологической конференции. Секция: «Формальные методы анализа русской речи». Март 2009. СПбГУ: СПб. С. 66–75.
Ввиду большого количества паралингвистических явлений в звучащей речи, список помет, используемых при базовом аннотировании корпуса, был существенно расширен. В частности, введены новые символы: *О – вздох, *Х – выдох, *З – зевок, *Ц – цыканье, *N – отрицание с закрытым ртом, *S – шмыганье носом, *G – гортанные неречевые звуки, *Г – причмокивание и др. Введены также новые обозначения для маркирования незавершенных реплик, продолжающихся после паузы.
Принято решение о необходимости анонимизации имен, фамилий и другой личной информации, касающейся говорящих, которая представлена в текстовых расшифровках. Для маркировки элементов, подлежащих анонимизации, введена дополнительная помета «%».
Рабочее окно аннотатора ELAN с фрагментом расшифровки звукозаписи
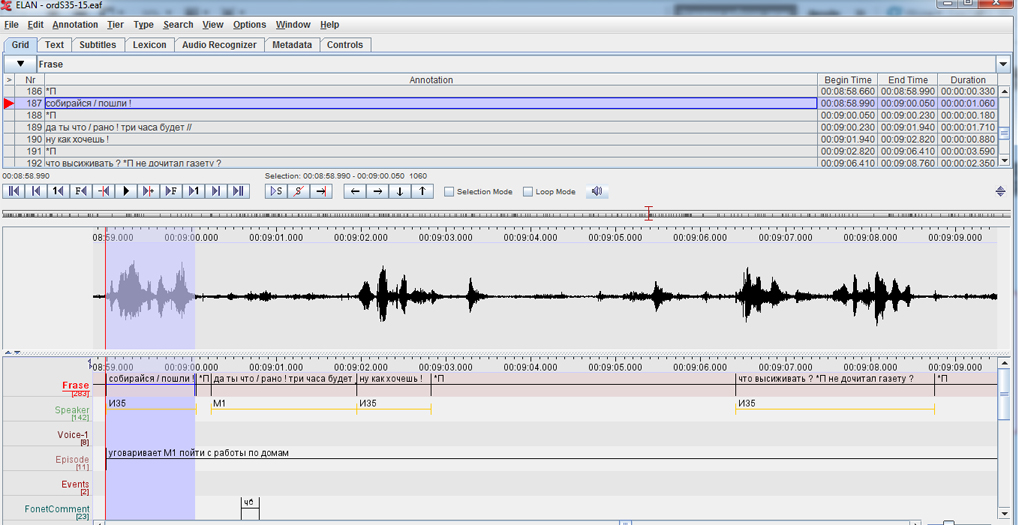
Этап III. Экспертное редактирование транскриптов в среде ELAN предполагает: 1) проверку и исправление расшифровки звукозаписи, 2) экспертную коррекцию границ сегментов и фразового/синтагматического членения, а также 3) проверку соответствия транскрипта конвенциям ОРД (заполнение обязательных полей, сегментация без использования точек и запятых, но с использованием знаков «!», «?», «/», «//», отсутствие зазоров между боксами, указание на паузы разной длительности, указание на шумы, указание на обрывы слов, указание на звуковые фрагменты, интерпретация которых множественна или затруднена, указание на паралингвистические явления, указание на смену дикторов, строгое соответствие помет конвенциям, орфографическая правильность записи словоформ – за исключением аллегровых форм). Важность экспертного редактирования не только состоит в обеспечении выверенных расшифровок, но и является необходимым условием корректного осуществления процедур обработки данных (в частности, автосегментирования речи на слова и аллофоны).
Процесс расшифровки с аннотированием, а также экспертное редактирование ее результатов представляет собой наиболее трудозатратную задачу, так как в среднем для получения 100 словоформ расшифровки с аннотированием требуется 1 час работы обученного специалиста, а темп экспертной работы в большой степени зависит от количества участников эпизода и доли сегментов с одновременной речью разных говорящих.
МЕТОДИКА ПОДГОТОВКИ РЕЧЕВОГО МАТЕРИАЛА К АВТОМАТИЧЕСКОЙ ОБРАБОТКЕ
Выработана методика подготовки речевого материала к автоматической обработке, необходимой для дальнейшего лингвистического аннотирования, включающая в себя следующие этапы:
Этап I. Corrector. Все файлы формата *.eaf, в которых содержится информация о текстовых транскриптах звукозаписей и их первичном аннотировании, обрабатываются с помощью программной утилиты Corrector (собственная разработка научного коллектива), позволяющей автоматически исправить возможные технические опечатки в транскриптах (например, убрать лишние пробелы), а также выявить возможные несоответствия между уровнями "Реплика" и "Говорящий" в случаях наложения речи нескольких говорящих. Наложения речи достаточно часто встречаются в повседневной речи и существенно затрудняют ее анализ. В случаях выявления несоответствий аннотаций для уровней "Реплика" и "Говорящий" проводится ручная (экспертная) коррекция соответствующих фрагментов расшифровок и повторный их анализ с помощью утилиты Corrector. Только полностью скорректированные файлы аннотации могут быть переданы на следующий уровень обработки.
Этап II. Eafer. Далее все файлы подкорпусов проходят обработку программой Eafer (также собственная разработка научного коллектива). С ее помощью осуществляется преобразование линейного одноуровневого представления речевого материала, принятого за основу транскрибирования корпуса ОРД с момента его основания, в многоуровневое представление, где каждый речевой уровень относится к одному говорящему (примерно так, как это делается при аннотировании речи в рамках исследований по конверсационному анализу (Conversation Analysis, CA)). Такой подход позволяет сепарировать речевой материал от разных говорящих, независимо от того, какое количество человек участвует в анализируемом разговоре и к каким социальным группам они принадлежат. При выявлении ошибок в атрибуции говорящих или в их кодовом представлении проводится ручная (экспертная) коррекция материала, после чего программа Eafer запускается повторно. Если в макроэпизоде участвует большое количество говорящих (например, учебная группа), но объем речи отдельных говорящих ограничивается одной или несколькими репликами, непредставительные объемы речевой продукции говорящих из одной социальной группы записываются на одном, объединенном, уровне. В остальных случаях на выходе получаются "разведенные по дикторам" тексты.
Этап III. Ручная коррекция границ аннотаций. На следующем этапе выполняется ручная коррекция границ боксов аннотаций для тех реплик, в которых есть одновременная речь двух и более говорящих. Эта процедура необходима для осуществления автоматического сегментирования звуковой волны на слова и аллофоны по транскрипту звукозаписи. Коррекция границ аннотаций осуществляется непосредственно в среде ELAN для каждого из уровней, содержащих реплики говорящих. После этого файлы аннотаций формата *.eaf считаются готовыми к автоматической обработке.