БАЗА ДАННЫХ
Для поддержки основных задач проекта разработана информационная база данных SocialStudies в формате MS Access 2007. В базе данных представлены как новые записи, выполненные в процессе реализации проекта, так и записи из корпуса ОРД, сделанные до начала проекта. I группа отражает социологические характеристики информантов и звукозаписи, заимствованные для проведения данного исследования из корпуса ОРД (записи 2007-2012) для 40 основных информантов. Названия таблиц первой группы имеют префикс ORD. II группа данных отражает социологические характеристики информантов и звукозаписи, выполненные в рамках данного проекта (запись 2014-2016 г.). Названия этих таблиц имеют префикс SOC и в них уже представлены данные по 88 информантам:
• SOC- Monitoring — мониторинг процесса звукозаписи,
• SOC-Informants — социологическая информация об информантах,
• SOC-Communicants — социологическая информация о коммуникантах,
• SOC- Episodes — макроэпизоды речевой коммуникации.
Таблица SOC-Monitoring создана для ведения мониторинга процесса звукозаписи. В ней представлены следующие поля описания:
• SCode: код информанта (записи 2014 г. имеют коды S60-S125),
• SName: псевдоним информанта (все записи выполняются как анонимные),
• SGender: пол информанта,
• SAge: возраст информанта на момент записи,
• SProf: профессия или род деятельности информанта,
• Date: дата записи,
• Instructor: инструктор, ответственный за запись информанта,
• TTime: общее количество часов, записанных информантом,
• SProf: профессия или род деятельности информанта,
• Comm: комментарий по проведению записи, а также другая вспомогательная информация.
Таблица SOC-Informants (Информанты) представляет собой данные, полученные из социологической анкеты информантов:
• SCode: код информанта,
• Gender: пол информанта,
• Age: возраст информанта на момент записи,
• PBirth: место рождения,
• Gender: пол информанта,
• MLang: родной язык (на данном этапе исследования записывались исключительно информанты, для которых русский язык является родным),
• Langs: другие языки, которыми владеет информант (информация, полезная для анализа влияния фактора интерференции),
• Nat: национальность родителей (по желанию),
• SClass: социальное происхождение (заполнялось в свободной форме — напр., рабочие, служащие, военные, музыканты и т.д.),
• Edu: уровень образования (среднее специальное, высшее и т.п.),
• Diploma: квалификация (специальность) информанта по диплому,
• PProf: прошлые профессии или опыт работы,
• Prof: профессия или род деятельности в настоящее время,
• Regions: места длительного проживания,
• Comments: комментарии.
Для оптимизации компьютерной обработки данных для некоторых параметров введены дополнительные поля, содержащие нормализованные коды:
• AgeGroup: возрастная группа,
• PBirthN: место рождения нормализованное,
• EduN: уровень образования нормализованный,
• ProfGroup: доминантная профессиональная группа (род деятельности),
• Status: социальное положение,
• ProfGroupExt: профессиональная группа (расширенная). Поскольку выяснилось, что определенный процент информантов в настоящее время работает не по той специальности, по которой они получали образование, а также многие информанты в настоящий могут быть отнесены к нескольким профессиональным группам (напр., преподаватель истории в вузе относится одновременно и к группе работников образования и группе представителей гуманитарных наук), в данном столбце в базе данных представлены все релевантные коды.
Таблица SOC-Communicants (коммуниканты) также представляет собой данные, полученные из социологической анкеты, заполняемой в процессе звукозаписи. Поля описания в основном совпадают с параметрами описания информантов, но содержат 2 дополнительных поля:
• SCode: код основного информанта обязательно указывается в дополнение к уникальному коду коммуниканта (CCode),
• CSRole: социальная роль коммуниканта по отношению к информанту.
Таблица SOC-Episodes (макроэпизоды речевой коммуникации) состоит из следующих полей описания:
• SCode: код говорящего;
• SFName: имя звукового файла;
• NComType: нормализованный тип коммуникативного эпизода;
• NSRole: социальная роль информанта в данном эпизоде (нормализованный код);
• NPlace: локус (место) коммуникации (нормализованный код);
• SFileOrig: имя исходного (архивного) файла;
• Start: начальная точка эпизода относительно начала исходного файла;
• End: конечная точка эпизода относительно начала исходного файла;
• EPlace: место коммуникации (текстовое описание);
• EAction: основное действие, сопутствующее разговору, или прагматическая задача;
• EWho: основные коммуниканты информанта в данном эпизоде;
• Duration: длительность эпизода (мин.);
• FonQuality: фонетическое качество в кодовом представлении (1 - максимальное);
• Priority: приоритет в расшифровке (ранговые пометы);
• SceneName: содержание эпизода и комментарии;
• ELAN: наличие транскрипта звукозаписи (логическое поле);
• DivSpeak: разведение расшифрованного файла по говорящим (логическое поле);
• Comments: комментарий.
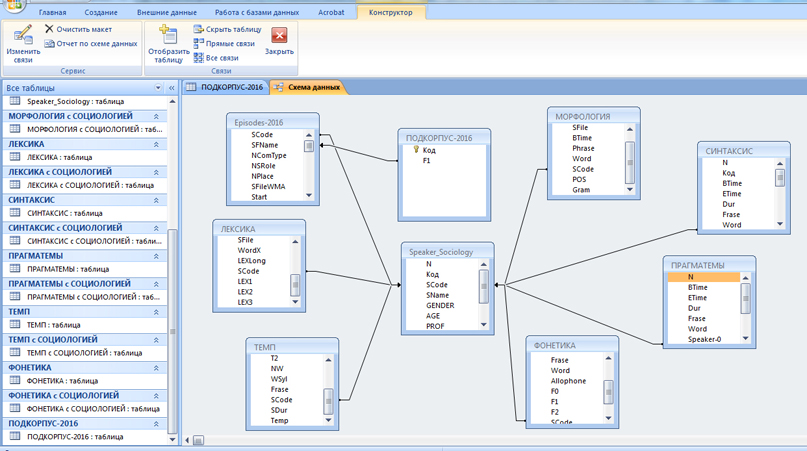
Для проведения социолингвистического исследования обе группы данных ORD и SOC объединены в таблицу Speaker_Socilogy. Результаты всех аннотаций по разным уровням сведены в единую базы данных и объединены с социологической информацией о говорящих (пол, возрастная группа, профессиональная группа, социальный статус). Получена статистическая информация о реализации каждого из проаннотированных параметров (дескриптивные статистики для числовых данных, доли/проценты для номинальных данных) в целом по подкорпусу и для каждой из анализируемых 20 социальных групп: 2-х гендерных, 3-х возрастных (молодежная группа (18-30 лет), средняя группа (31-54), старшая группа (55 лет и старше), 10-ти профессиональных групп (рабочие, инженеры, военнослужащие, представители естественных наук, представители гуманитарных наук, работники образования, представители сферы обслуживания, IT-специалисты, офисные служащие, творческая интеллигенция) и 5-ти статусных групп (студенты и учащиеся, наемные работники и специалисты, руководящие работники, бизнесмены и частные предприниматели, неработающие и пенсионеры). Осуществлена статистическая проверка значимости полученных результатов с помощью стандартных статистических критериев (критерий Стьюдента, критерий хи-квадрат, критерий проверки значимости коэффициента корреляции Спирмена и др.), проверены выдвинутые статистические гипотезы о существенности различий языка повседневного общения разных социальных групп по анализируемым параметрам, показавшим видимые отличия.
Структура данных для многоуровневого социолингвистического исследования